Authors: Mutian He, Yan Deng, Lei He
Abstract: Neural TTS has demonstrated strong capabilities to generate human-like speech with high quality and naturalness, while its generalization to out-of-domain texts is still a challenging task, with regard to the design of attention-based sequence-to-sequence acoustic modeling. Various errors occur in those texts with unseen context, including attention collapse, skipping, repeating, etc., which limits the broader applications. In this paper, we propose a novel stepwise monotonic attention method in sequence-to-sequence acoustic modeling to improve the robustness on out-of-domain texts. The method utilizes the strict monotonic property in TTS with extra constraints on monotonic attention that the alignments between inputs and outputs sequence must be not only monotonic but also allowing no skipping on the inputs. In inference, soft attention could be used to evade mismatch between training and test in monotonic hard attention. The experimental results show that the proposed method could achieve significant improvements in robustness on various out-of-domain scenarios, without any regression on the in-domain test set.
Scripts: Common DB connectors include the DB - 9, DB - 15, DB - 19, DB - 25, DB - 37, and DB - 50 connectors.
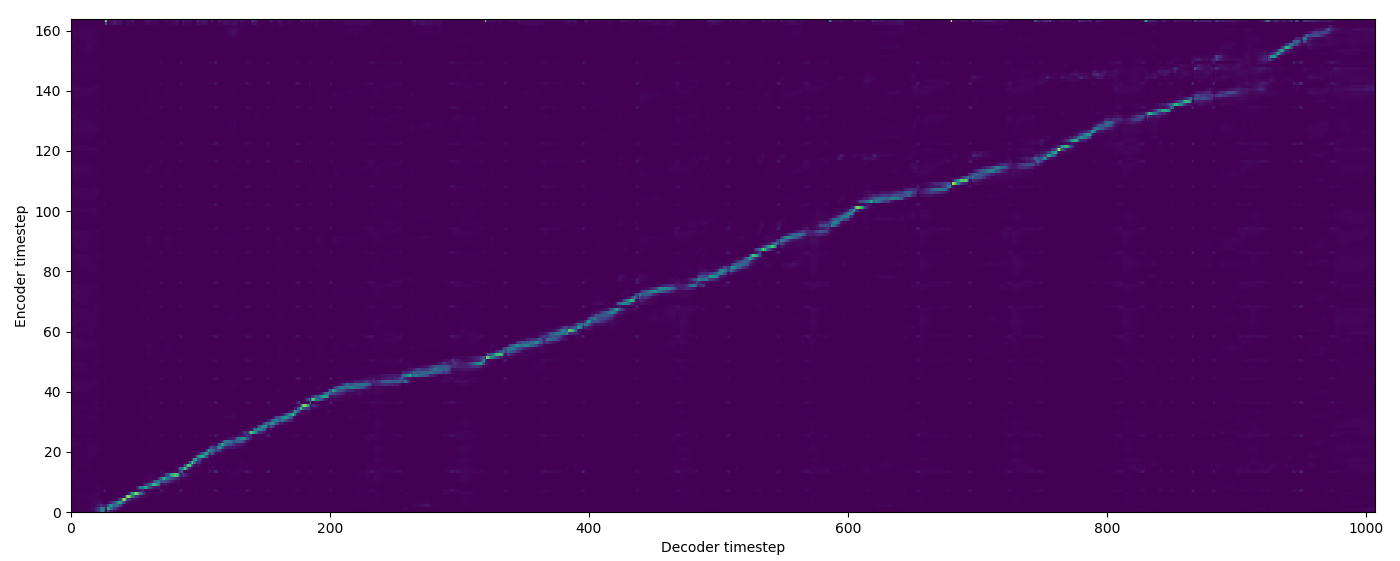
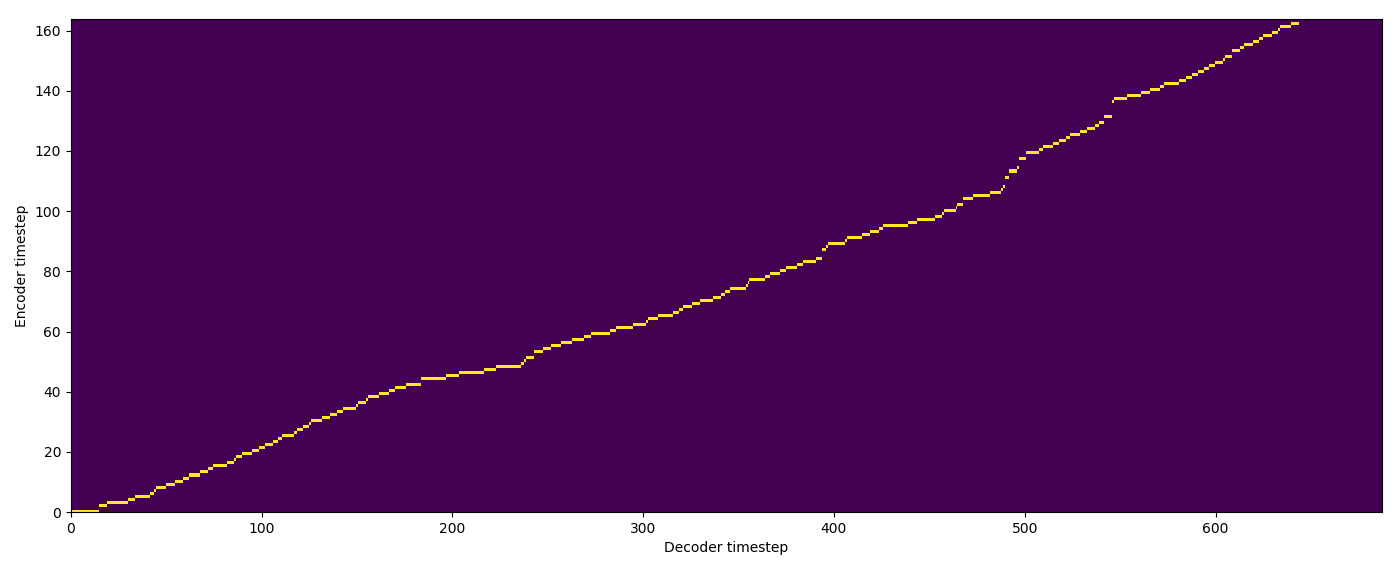
| Model | Audio | Alignments |
|---|---|---|
| Baseline | |
|
| FA w/o TA | |
|
| FA+TA | |
|
| GMM | |
|
| MA hard | |
|
| MA soft | |
|
| SMA hard | |
|
| SMA soft | |
Scripts: The accusation that a particular critical remark is "irrelevant" to its object is one of the most frequently heard in discussion and debate among critics. Frequently heard because frequently correct: there has never been a dearth of criticism that carelessly relates a work to an artist's biography, or employs pointless historic speculation, or invokes inappropriate creative standards, or describes the critic's own fuzzy reveries to misdirect our attention and obscure the essential significance of the object before us.
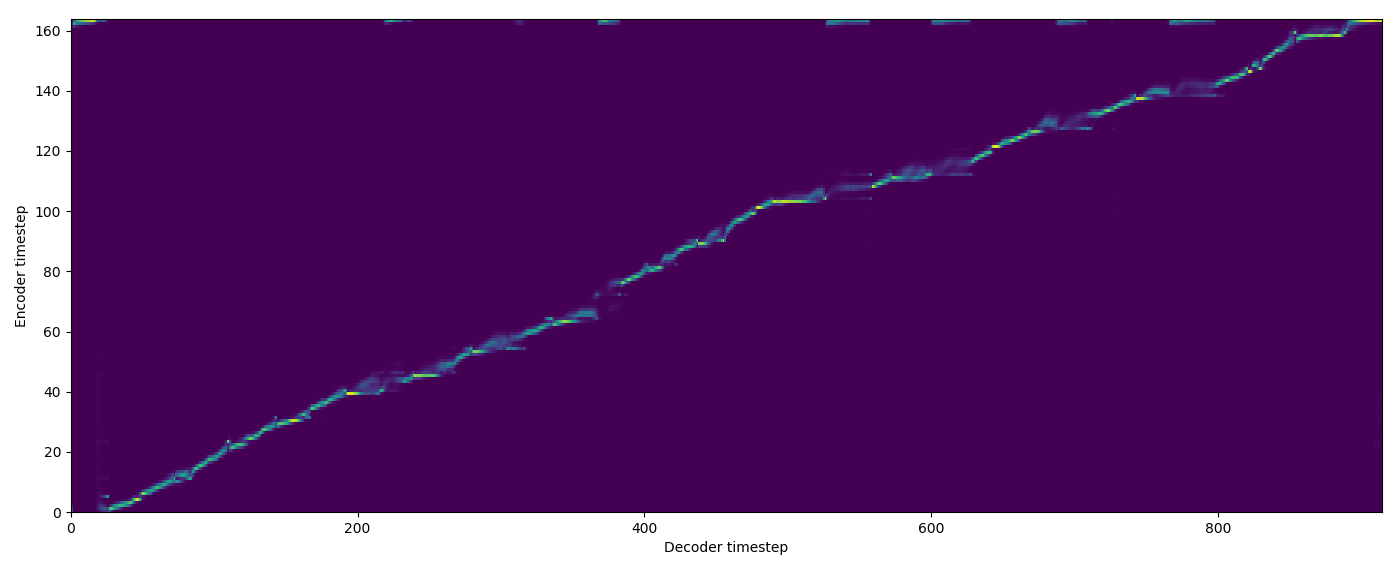
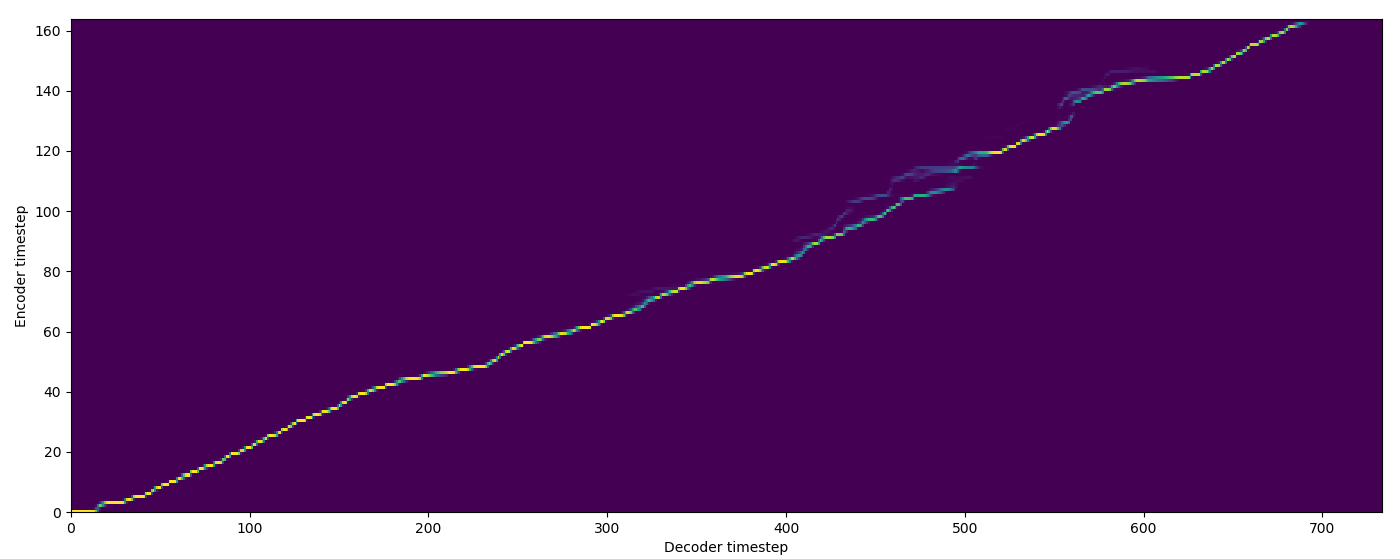
| Model | Audio | Alignments |
|---|---|---|
| Baseline | 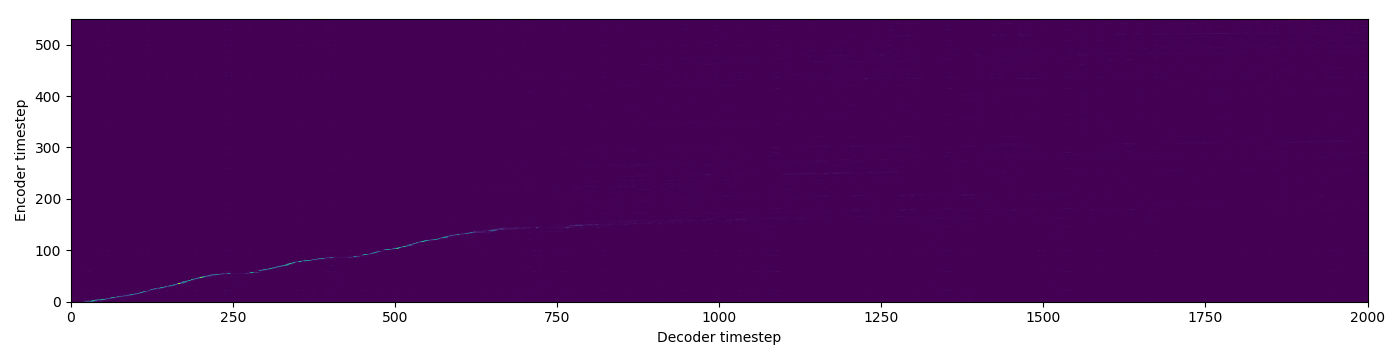 |
|
| FA w/o TA | 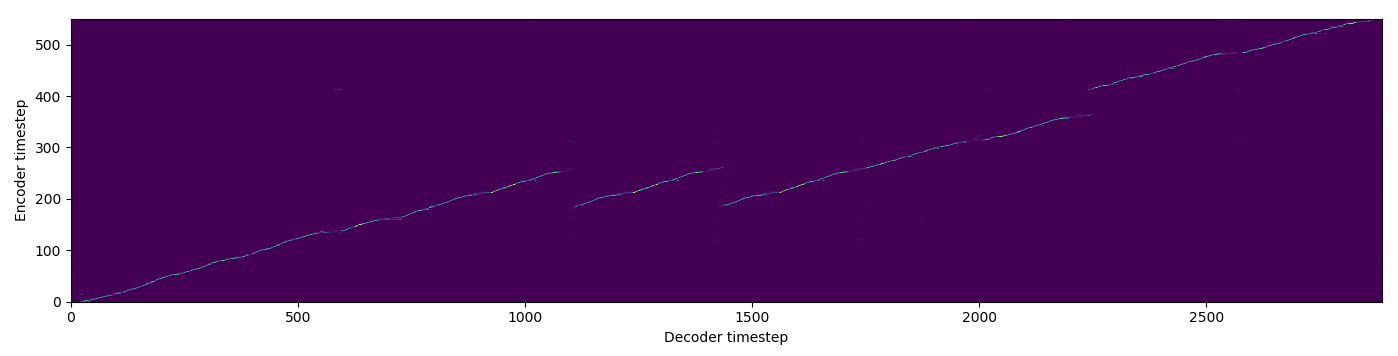 |
|
| FA+TA | 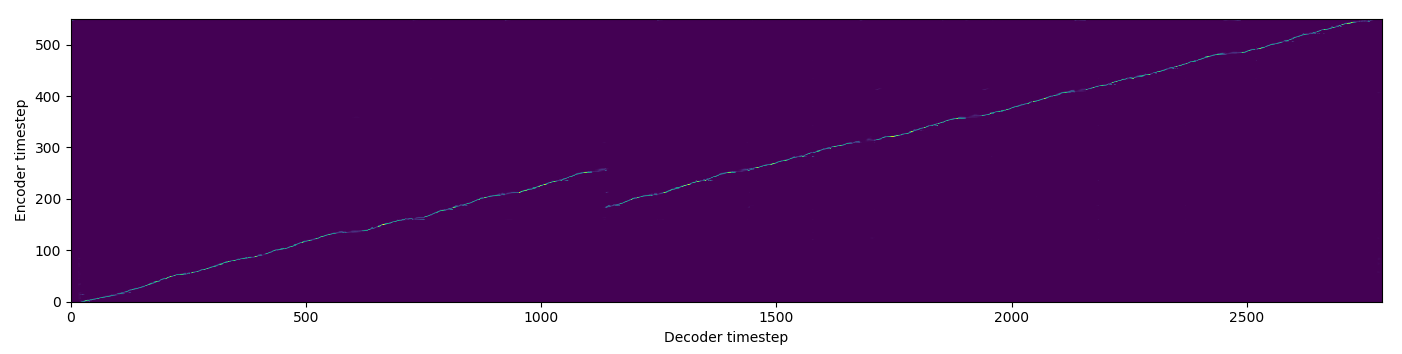 |
|
| GMM | 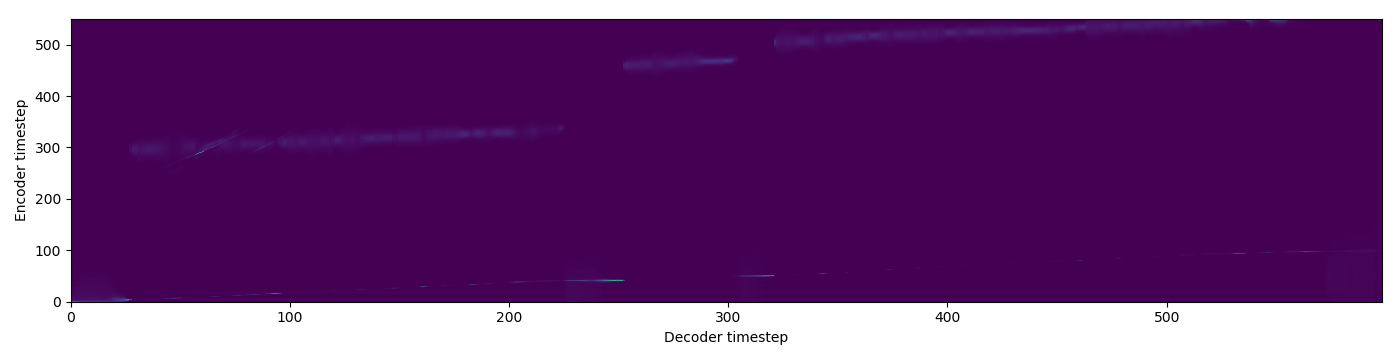 |
|
| MA hard | 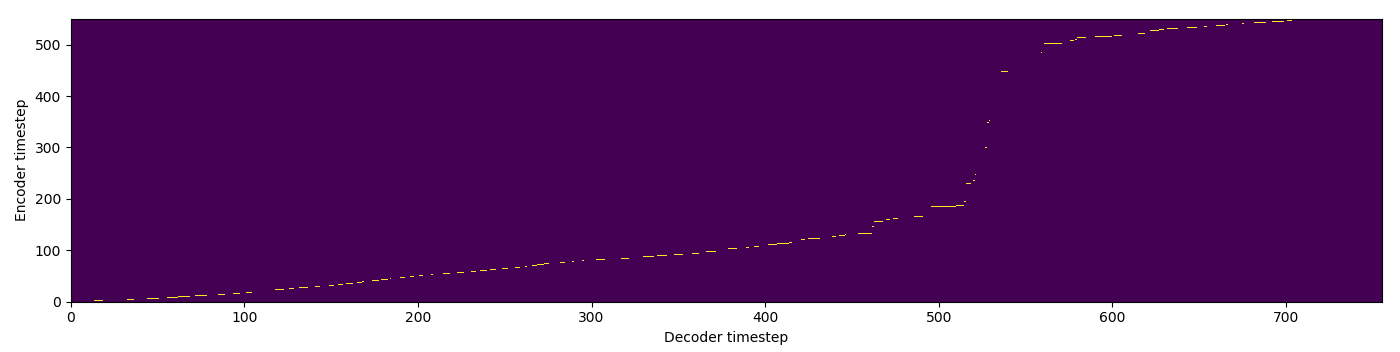 |
|
| MA soft | 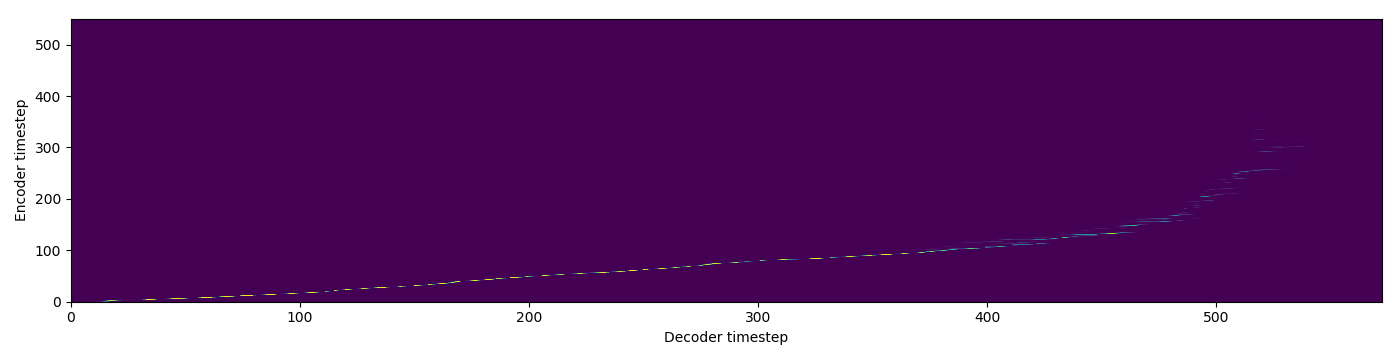 |
|
| SMA hard | 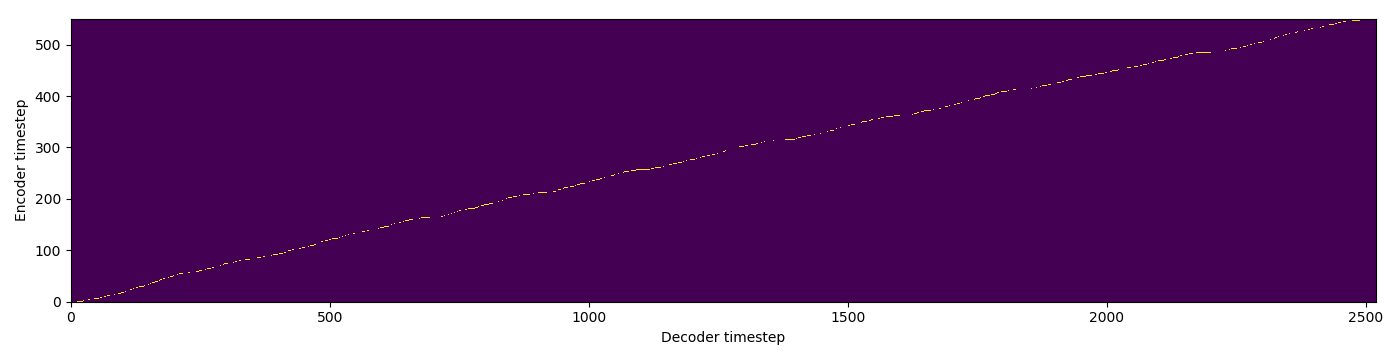 |
|
| SMA soft | 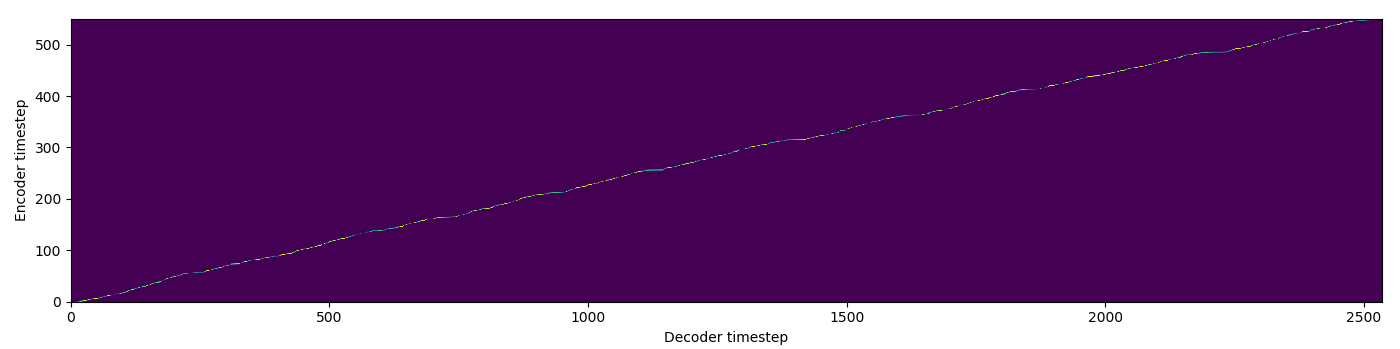 |
Scripts: The preliminary ruling by Judge Lucy in the U.S. District Court for the Northern District of California said that Qualcomm must license some patents involved in making so-called modem chips, which help smart phones connect to wireless data networks, to rival chip firms. The ruling is a setback for Qualcomm because the chip company and the FTC had jointly asked the judge last month to delay ruling on the issue for up to 30 days while they pursued settlement talks.
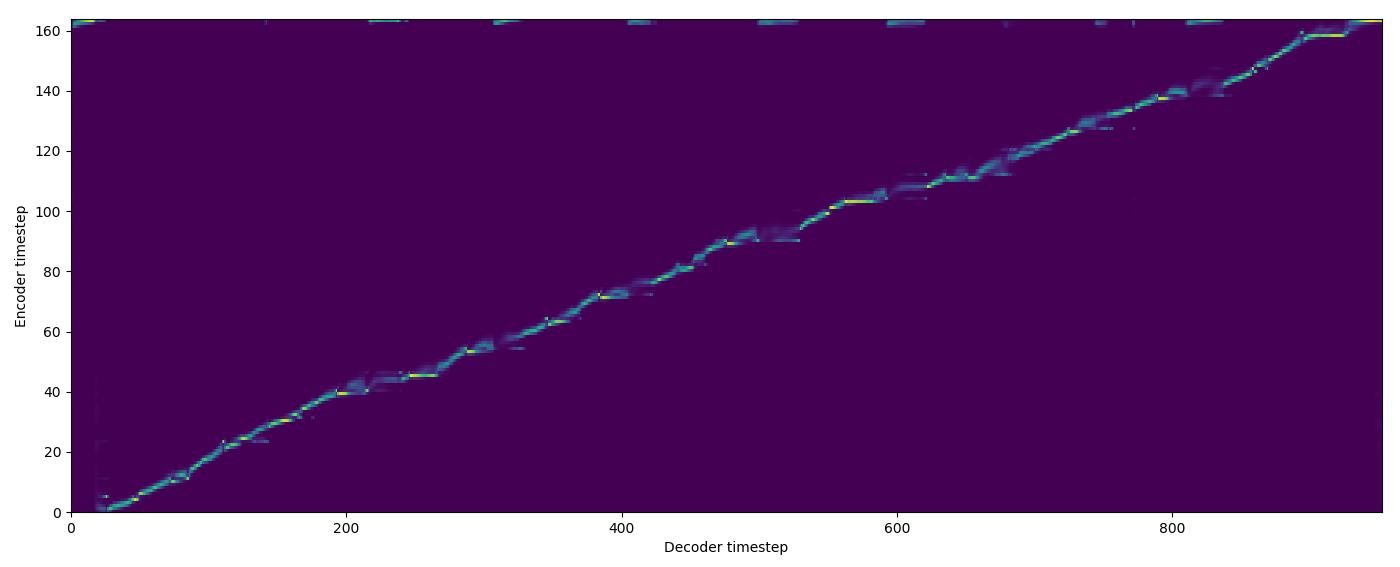
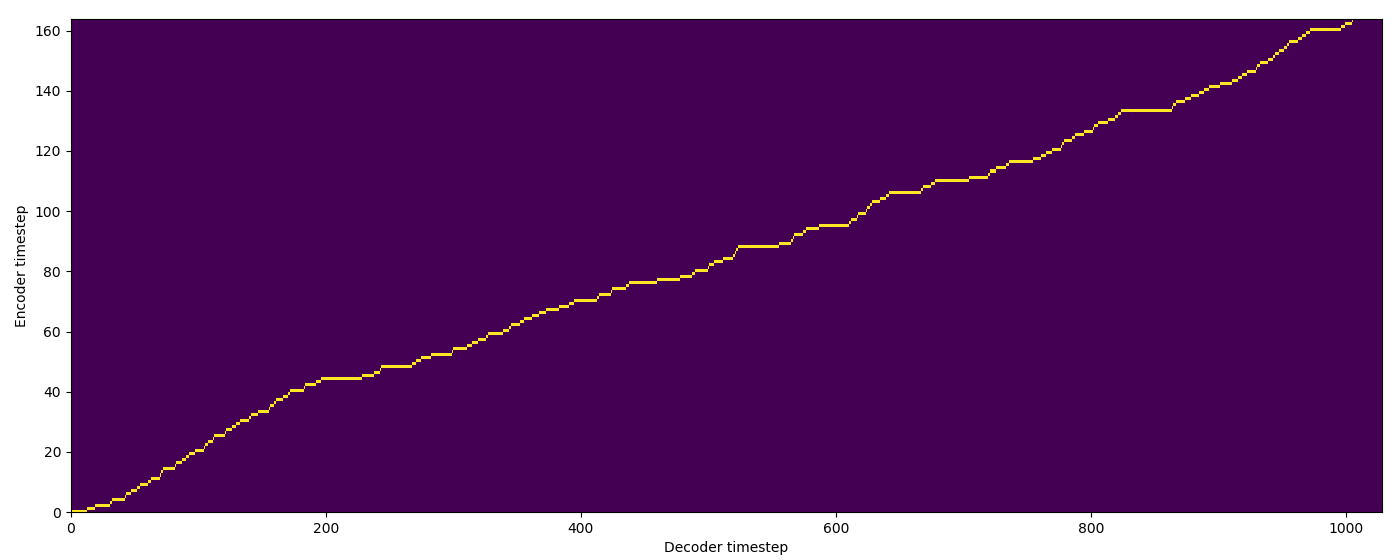
| Model | Audio | Alignments |
|---|---|---|
| Baseline | 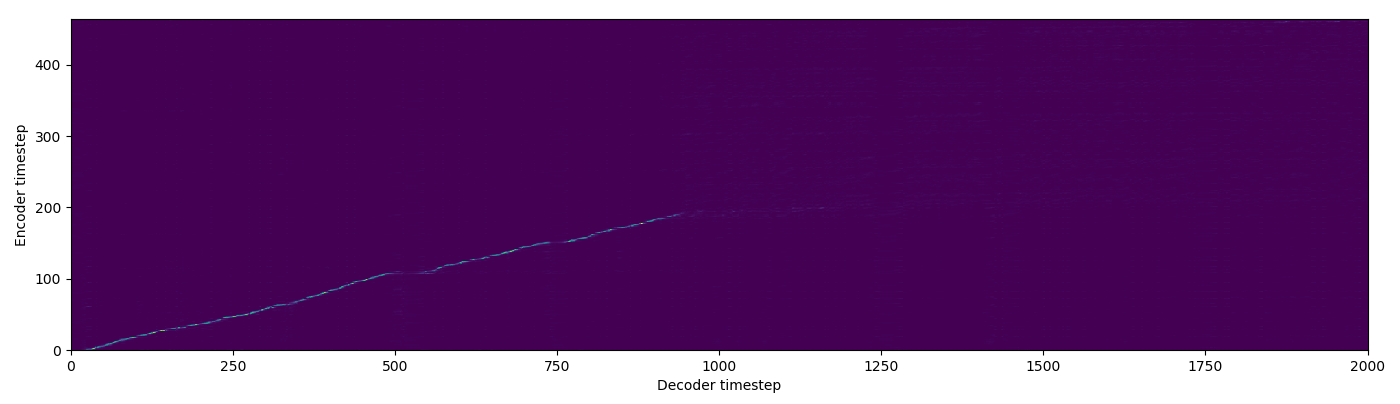 |
|
| FA w/o TA | 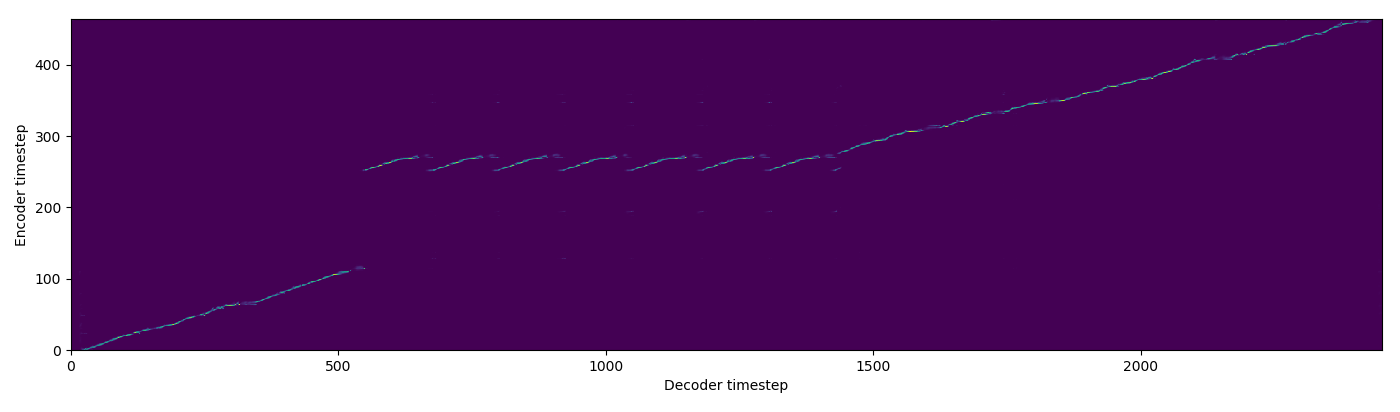 |
|
| FA+TA | 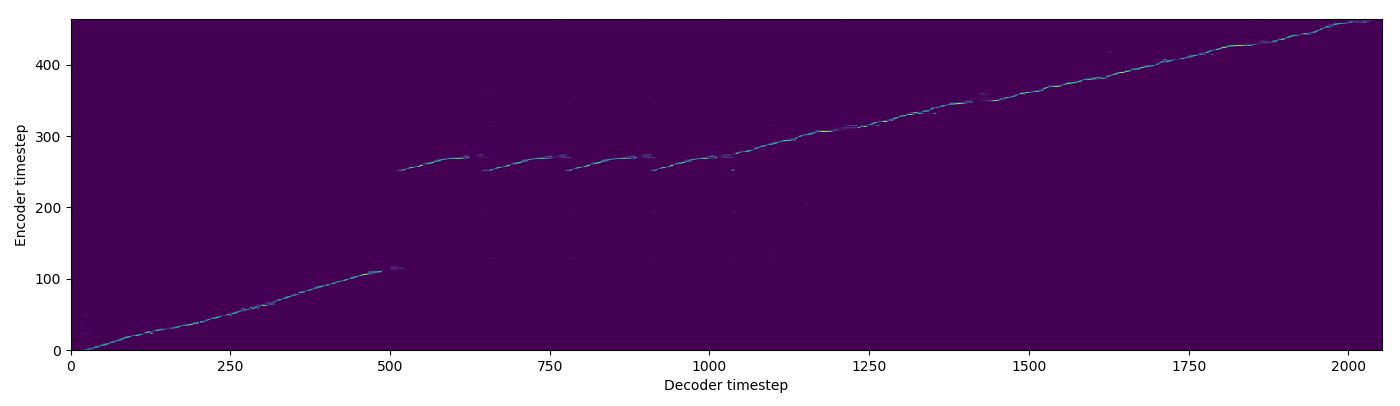 |
|
| GMM | 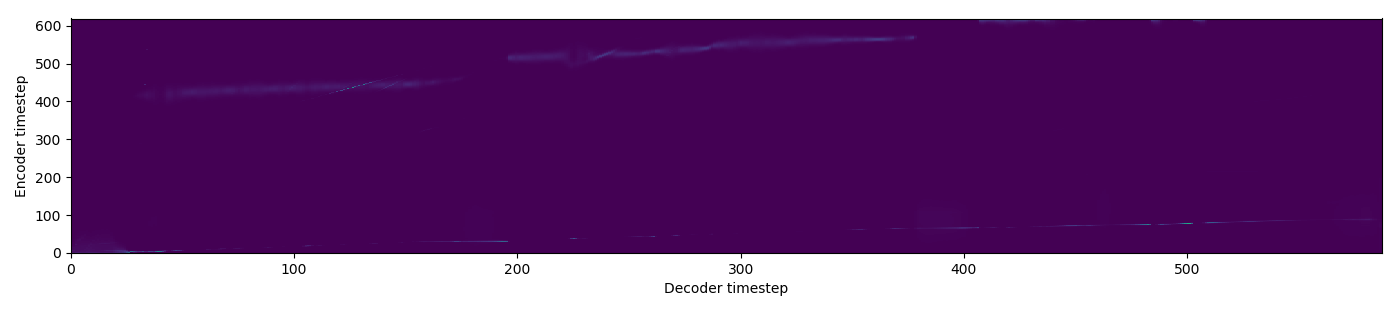 |
|
| MA hard | 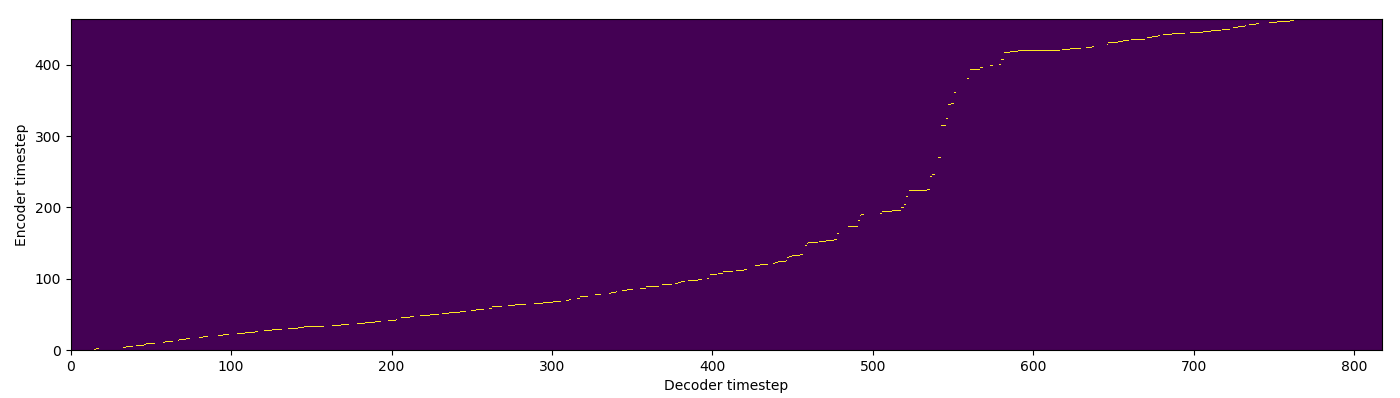 |
|
| MA soft | 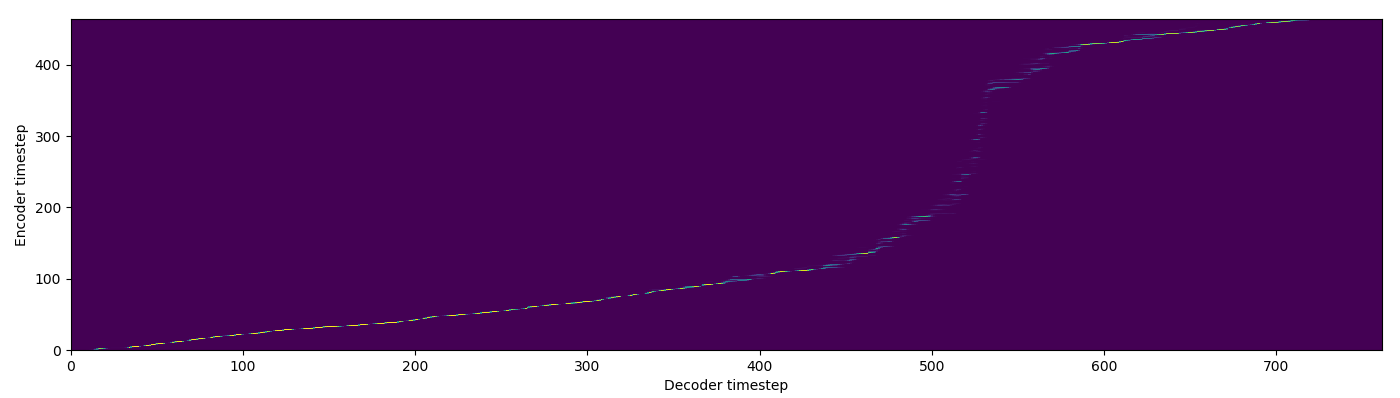 |
|
| SMA hard | 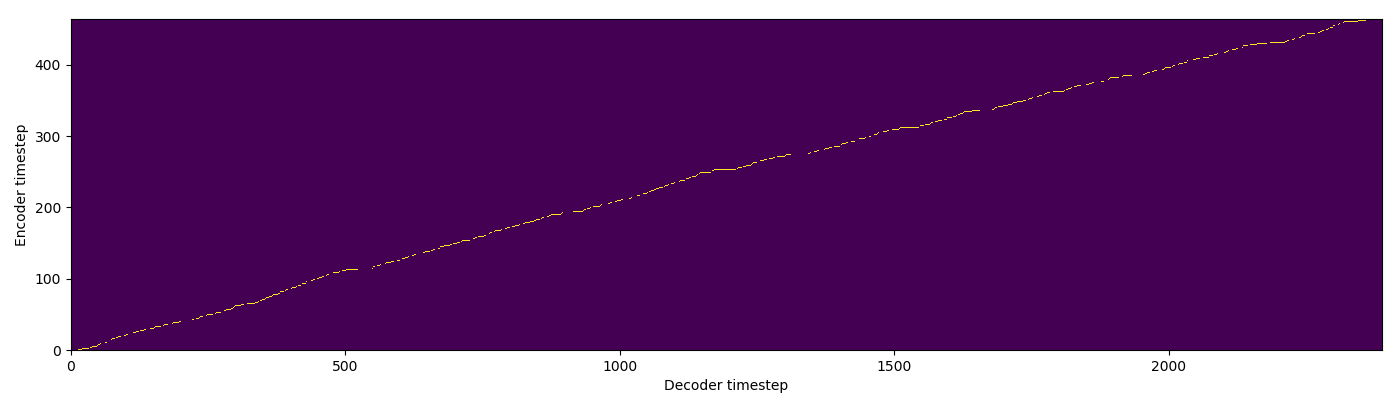 |
|
| SMA soft | 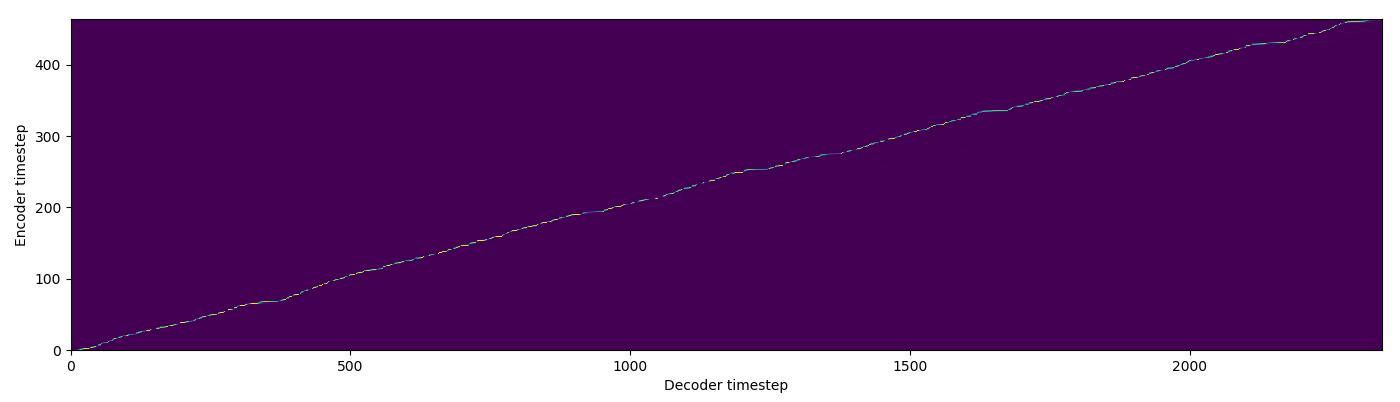 |
Scripts: Crashes \ ReadAVs \ 00000000 \ foo , doc WriteAVs \ 11111111 \ foo 2 , doc: That makes post-processing a little painful since the fuzzer reports crashes in the hierarchical structure mentioned above.
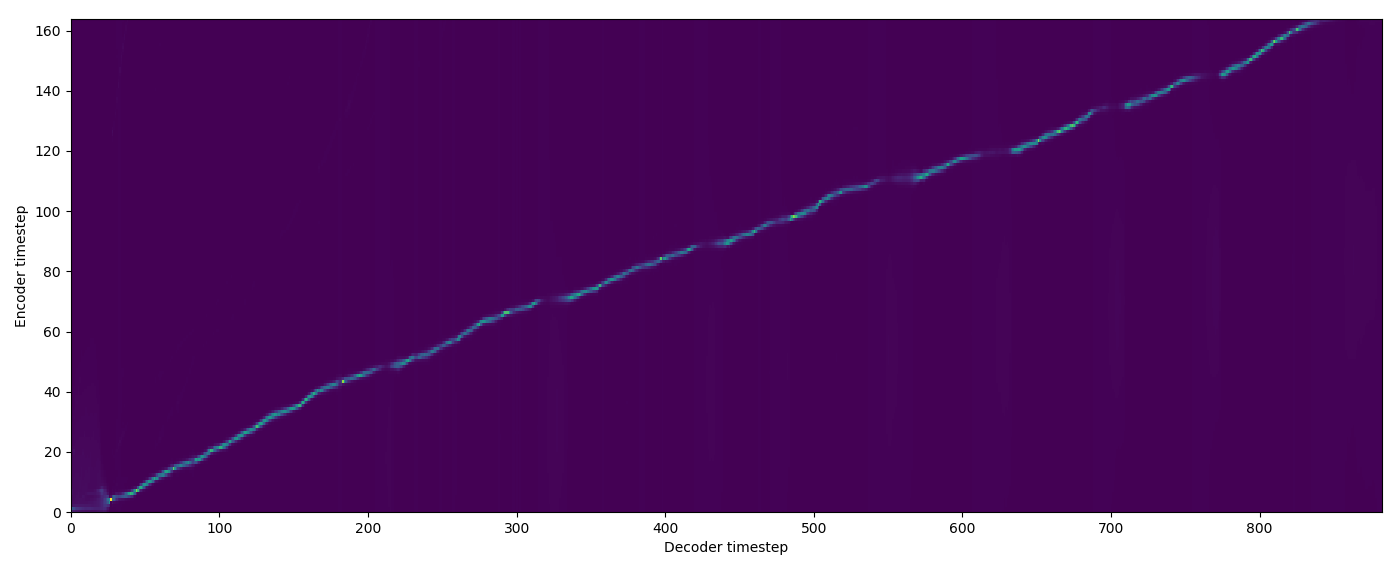
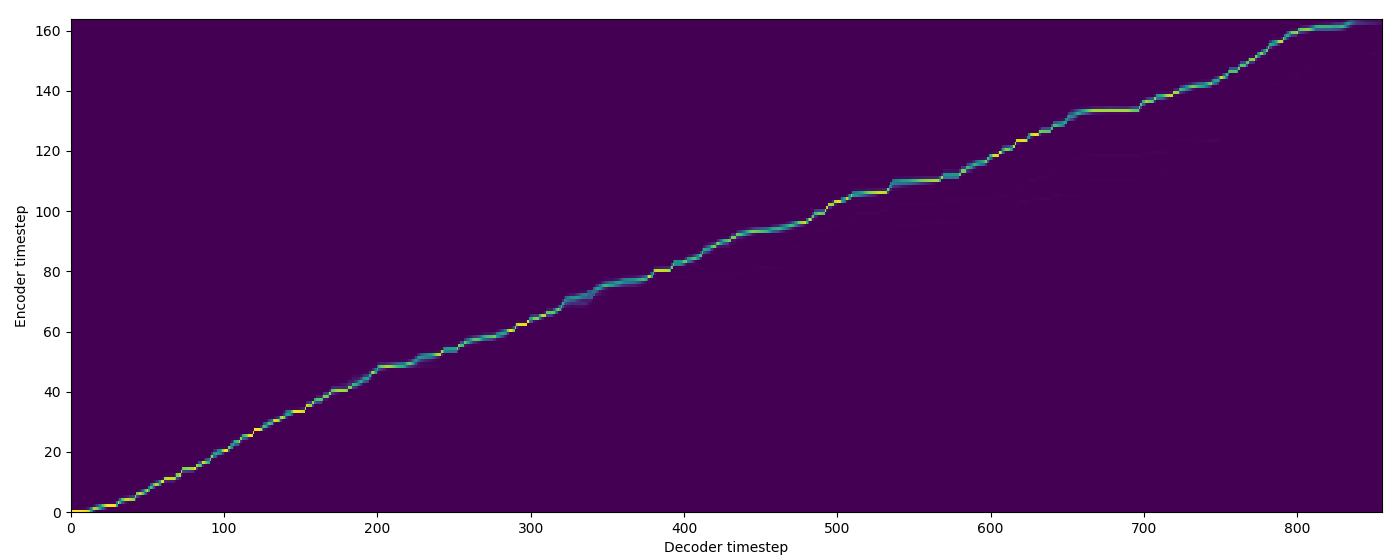
| Model | Audio | Alignments |
|---|---|---|
| Baseline | 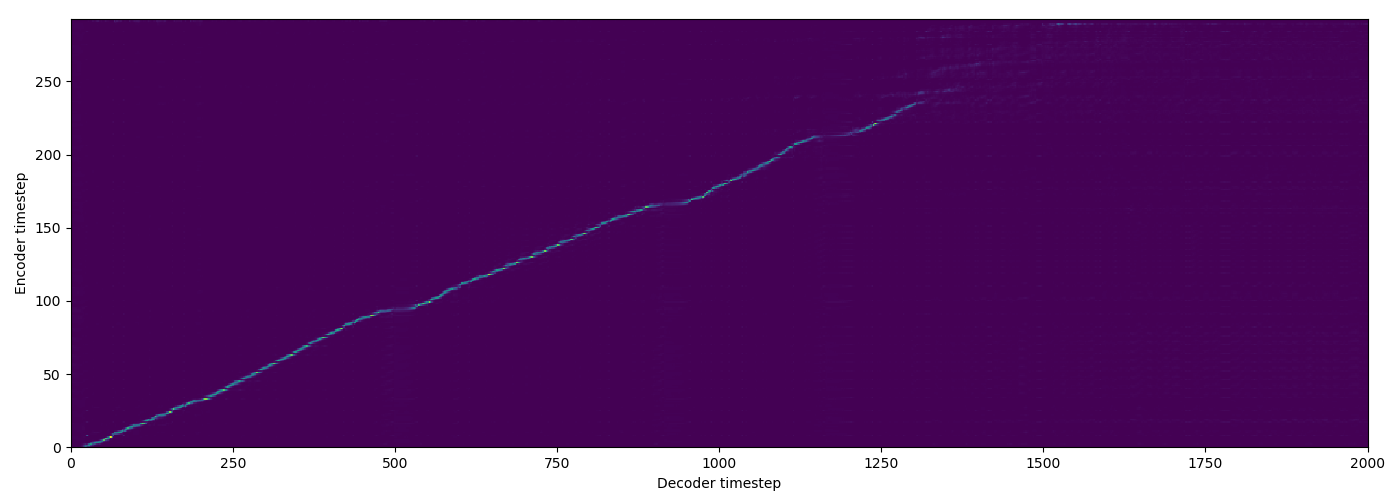 |
|
| FA w/o TA | 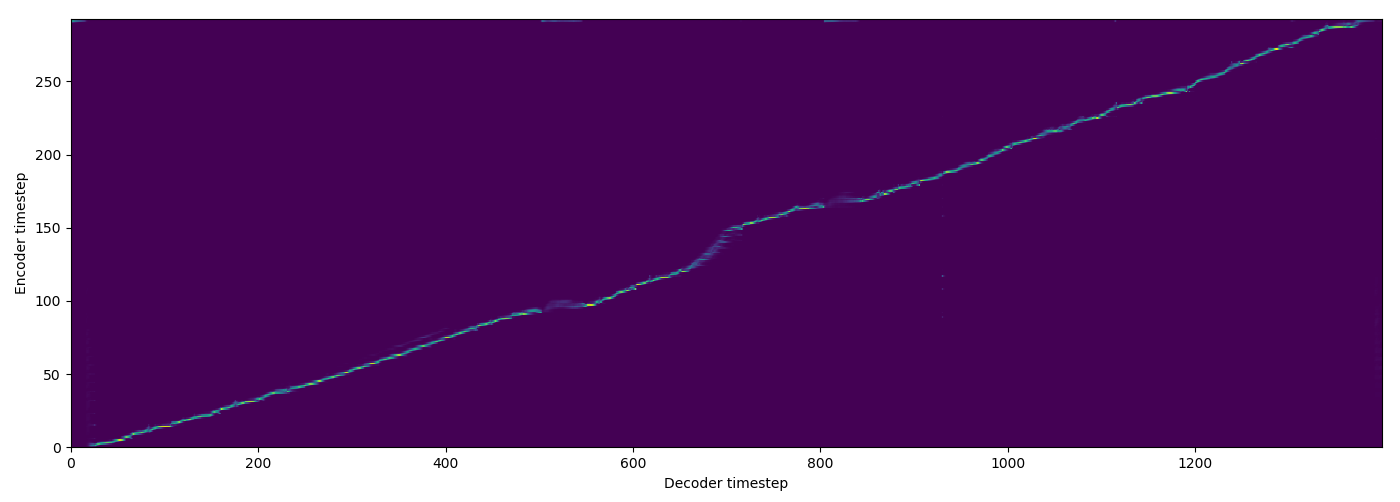 |
|
| FA+TA | 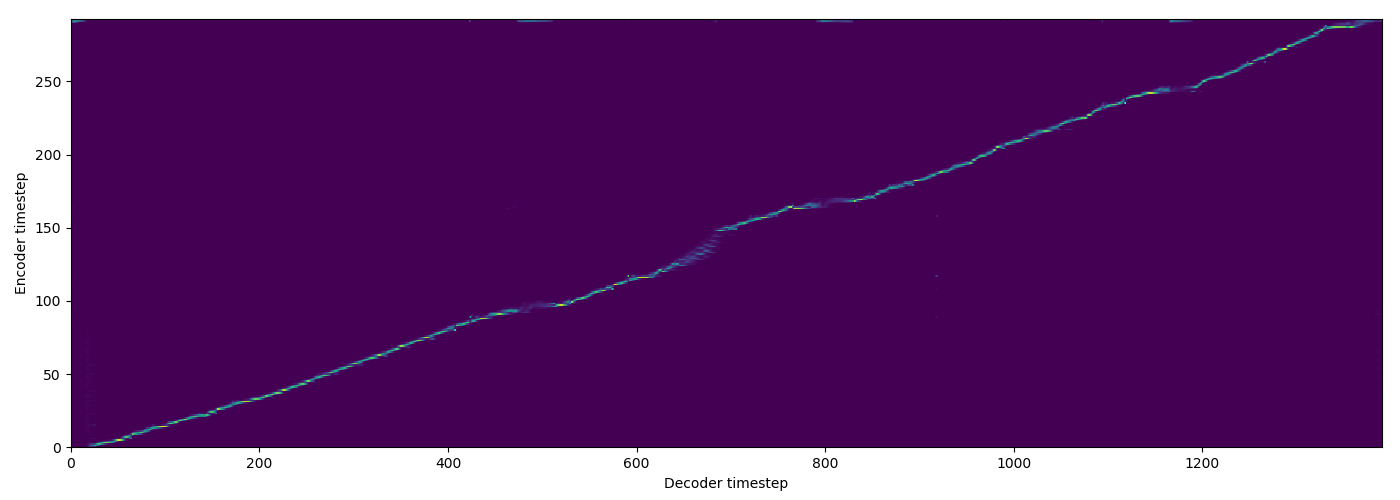 |
|
| GMM | 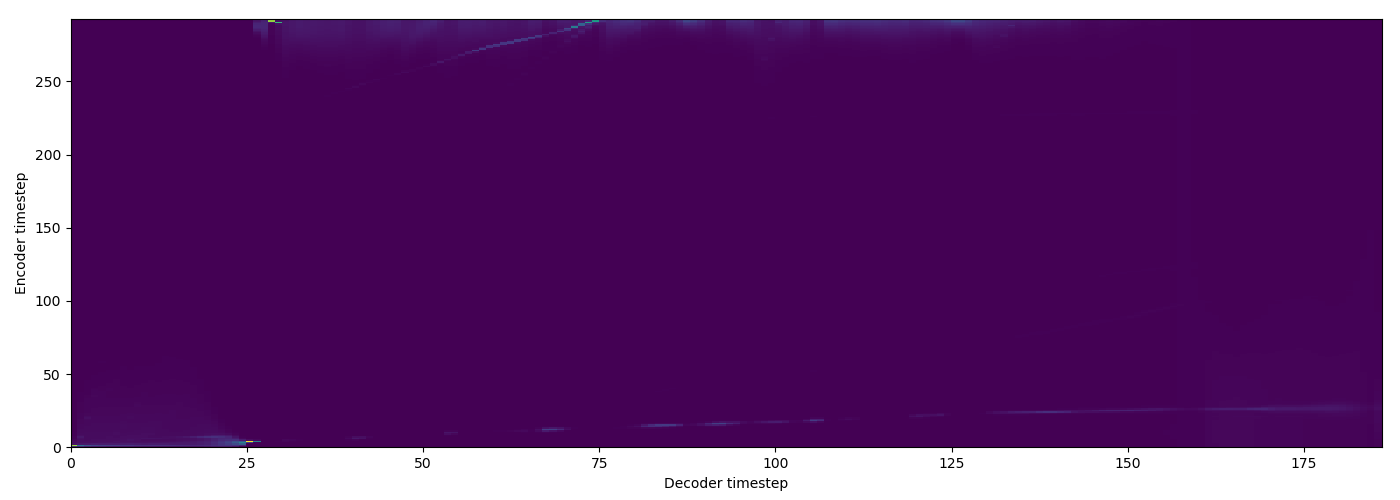 |
|
| MA hard | 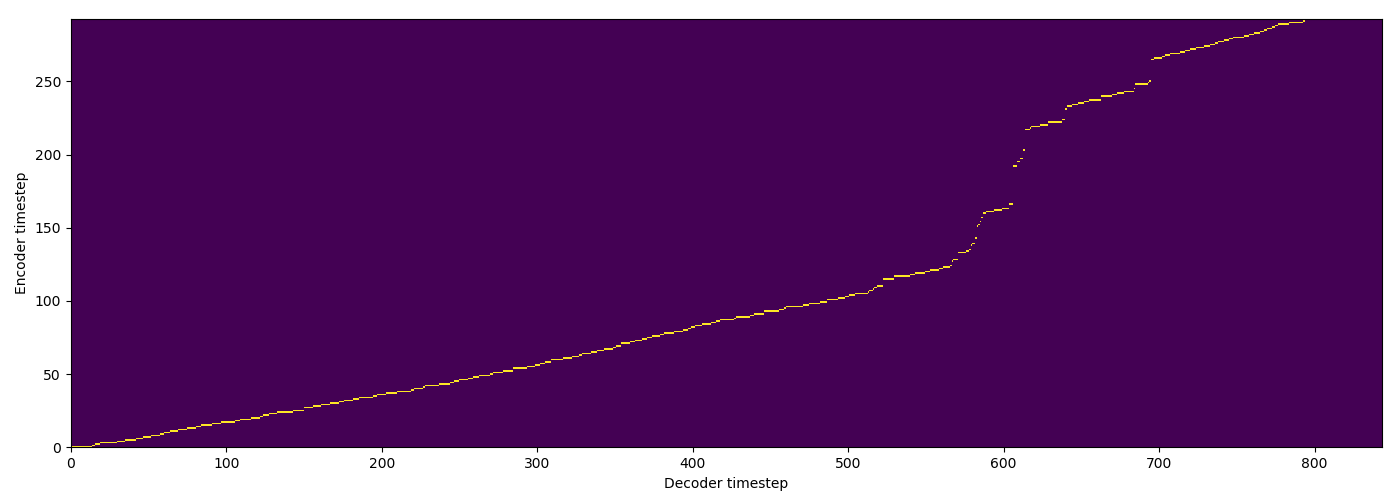 |
|
| MA soft | 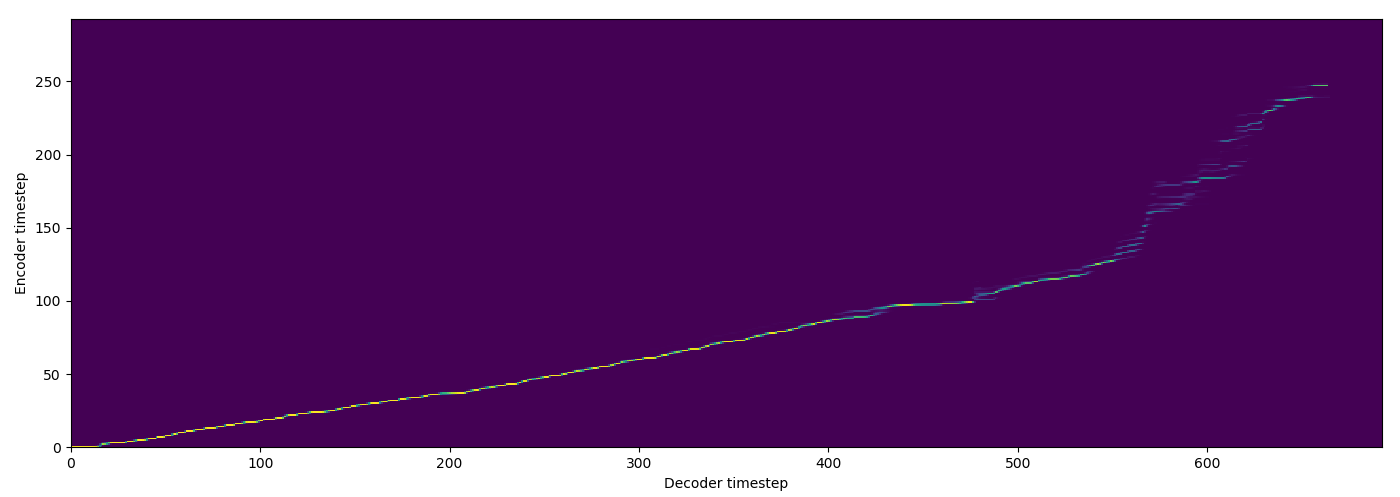 |
|
| SMA hard | 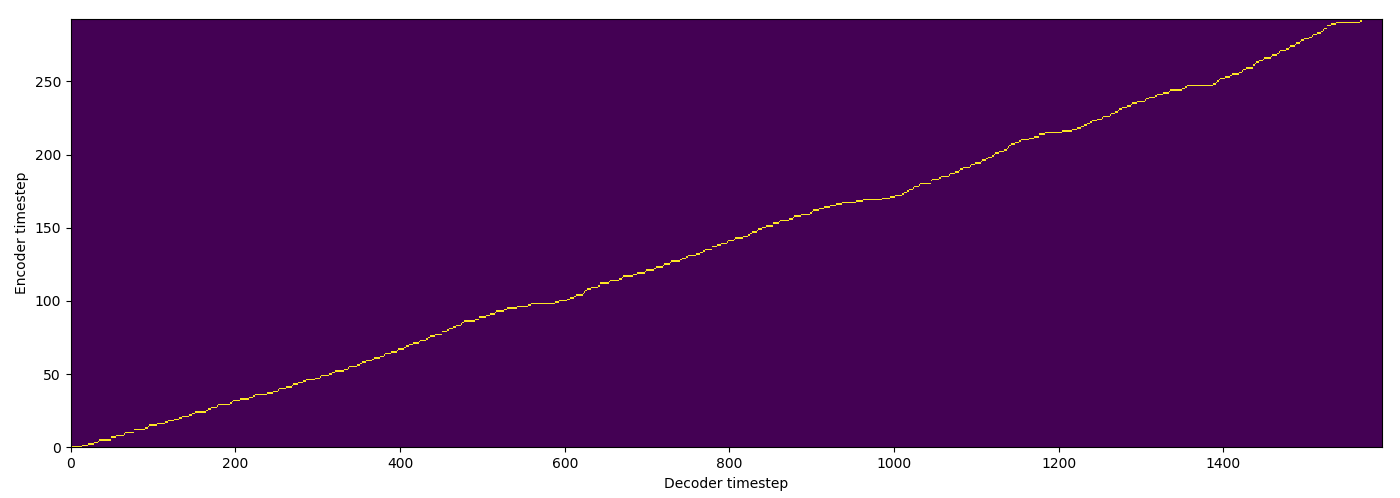 |
|
| SMA soft | 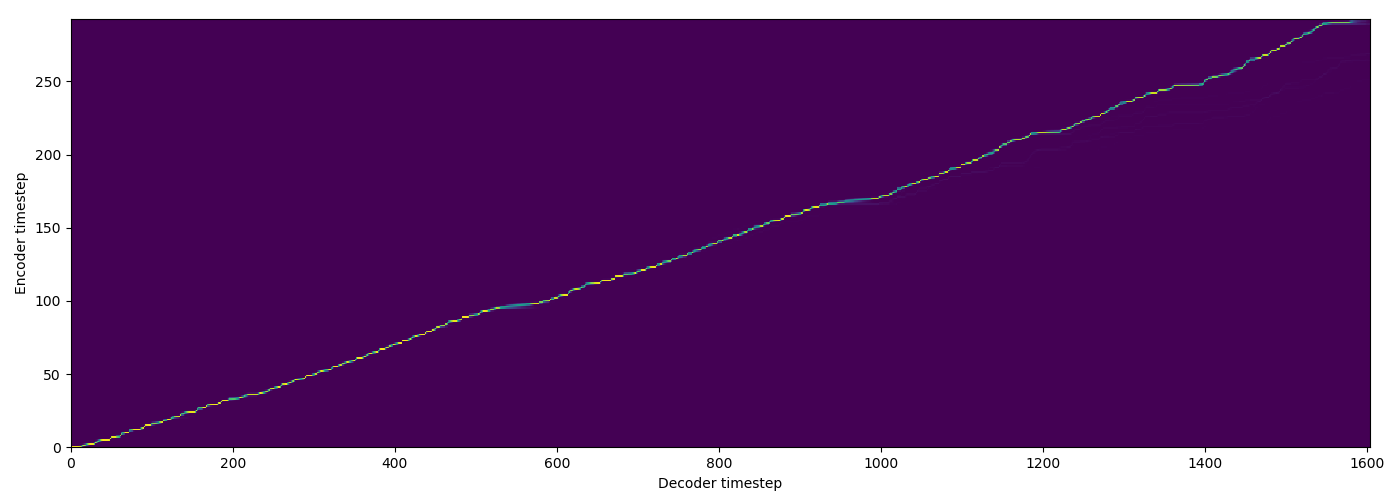 |
| Model | Audio | ||
|---|---|---|---|
| Baseline | |||
| FA w/o TA | |||
| FA+TA | |||
| GMM | |||
| MA hard | |||
| MA soft | |||
| SMA hard | |||
| SMA soft | |||
Below are some samples that demonstrate unnatural prosody with hard inference, presumably due to context mismatch as the issue could be avoided by its soft peer, and could be explained by that the model couldn't decide the correct prosody when it has no sight on future memories.
| Model | MA hard vs MA soft | SMA hard vs SMA soft | |
|---|---|---|---|
| Audio | vs | vs | vs |
| Scripts | One of his favorite videos features ballerinas wearing LED lights. | Europe and North America are soaking up every drop they can get. | Jackie wrote back: You and I share another bond - reminding our children all their lives what brave men their fathers were. |